下载二进制包:Download | Prometheus
安装prometheus
本文档使用LTS长期支持版:2.45.4
mkdir /usr/local/prometheus # 新建存放prometheus组件目录
# 安装
tar zxvf prometheus-2.45.4.linux-amd64.tar.gz -C /usr/local/prometheus
mv /usr/local/prometheus/prometheus-2.45.4.linux-amd64 /usr/local/prometheus/prometheus注册系统服务
vim /etc/systemd/system/prometheus.service[Unit]
Description=Prometheus Server
Documentation=https://prometheus.io/docs/introduction/overview/
After=network-online.target
[Service]
Type=simple
#User=prometheus
#Group=prometheus
Restart=on-failure
ExecStart=/usr/local/prometheus/prometheus/prometheus \
--config.file=/usr/local/prometheus/prometheus/prometheus.yml \
--storage.tsdb.path=/usr/local/prometheus/prometheus/data \
--storage.tsdb.retention.time=60d \
--web.enable-lifecycle
[Install]
WantedBy=multi-user.target启动并设置开机自启
systemctl enable prometheus --now检查状态
systemctl status prometheus验证
访问http://ip:9090,访问到即可。
安装alertmanager
tar zxvf alertmanager-0.27.0.linux-amd64.tar.gz -C /usr/local/prometheus
mv /usr/local/prometheus/alertmanager-0.27.0.linux-amd64 /usr/local/prometheus/alertmanager注册系统服务
vim /etc/systemd/system/alertmanager.service[Unit]
Description=Alert Manager
Wants=network-online.target
After=network-online.target
[Service]
Type=simple
#User=prometheus
#Group=prometheus
ExecStart=/usr/local/prometheus/alertmanager/alertmanager \
--config.file=/usr/local/prometheus/alertmanager/alertmanager.yml \
--storage.path=/usr/local/prometheus/alertmanager/data
Restart=always
[Install]
WantedBy=multi-user.target修改配置文件
vim /usr/local/prometheus/alertmanager/alertmanager.ymlroute:
group_by: ['dingtalk']
group_wait: 1s
group_interval: 5m
repeat_interval: 1h
receiver: 'dingtalk.webhook1'
routes:
- receiver: "dingtalk.webhook1"
match_re:
altername: ".*"
receivers:
- name: 'dingtalk.webhook1'
webhook_configs:
- url: 'http://localhost:8060/dingtalk/webhook1/send'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']启动并设置开机自启
systemctl enable alertmanager --now检查状态
systemctl status alertmanager验证
安装node_exporter
tar zxvf node_exporter-1.7.0.linux-amd64.tar.gz -C /usr/local/prometheus
mv /usr/local/prometheus/node_exporter-1.7.0.linux-amd64 /usr/local/prometheus/node_exporter注册系统服务
vim /etc/systemd/system/node_exporter.service[Unit]
Description=node_exporter
Documentation=https://prometheus.io/
After=network.target
[Service]
#User=prometheus
#Group=prometheus
ExecStart=/usr/local/prometheus/node_exporter/node_exporter
Restart=on-failure
[Install]
WantedBy=multi-user.target启动并设置开机自启
systemctl enable node_exporter --now检查状态
systemctl status node_exporter验证
访问http://ip:9100/metrics,监控数据存在即可。
安装grafana
下载地址:Grafana get started | Cloud, Self-managed, Enterprise
tar zxvf node_exporter-1.7.0.linux-amd64.tar.gz -C /usr/local/prometheus
mv /usr/local/prometheus/node_exporter-1.7.0.linux-amd64 /usr/local/prometheus/node_exporter注册系统服务
vim /etc/systemd/system/grafana-server.service[Unit]
Description=Grafana server
Documentation=http://docs.grafana.org
[Service]
Type=simple
#User=prometheus
#Group=prometheus
Restart=on-failure
ExecStart=/usr/local/prometheus/grafana/bin/grafana-server \
--config=/usr/local/prometheus/grafana/conf/defaults.ini \
--homepath=/usr/local/prometheus/grafana
[Install]
WantedBy=multi-user.target启动并设置开机自启
systemctl enable grafana-server --now检查状态
systemctl status grafana-server浏览器访问http://ip:3000,账号admin,密码admin,首次根据提示修改密码
添加监控
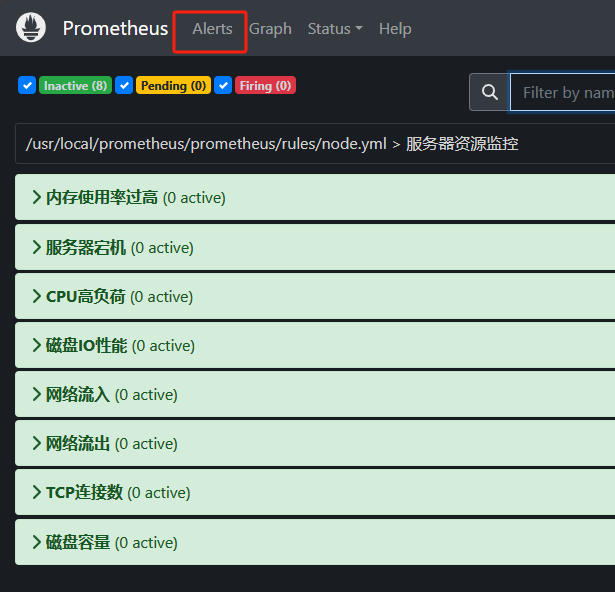
创建告警规则
mkdir -p /usr/local/prometheus/prometheus/rulesvim node.yamlgroups:
- name: 服务器资源监控
rules:
- alert: 内存使用率过高
expr: 100 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) * 100 > 80
for: 3m
labels:
severity: 严重告警
annotations:
summary: "{{ $labels.instance }} 内存使用率过高, 请尽快处理!"
description: "{{ $labels.instance }}内存使用率超过80%,当前使用率{{ $value }}%."
- alert: 服务器宕机
expr: up == 0
for: 1s
labels:
severity: 严重告警
annotations:
summary: "{{$labels.instance}} 服务器宕机, 请尽快处理!"
description: "{{$labels.instance}} 服务器node_exporter服务被关闭,当前状态{{ $value }}. "
- alert: CPU高负荷
expr: 100 - (avg by (instance,job)(irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 90
for: 5m
labels:
severity: 严重告警
annotations:
summary: "{{$labels.instance}} CPU使用率过高,请尽快处理!"
description: "{{$labels.instance}} CPU使用大于90%,当前使用率{{ $value }}%. "
- alert: 磁盘IO性能
expr: avg(irate(node_disk_io_time_seconds_total[1m])) by(instance,job)* 100 > 90
for: 5m
labels:
severity: 严重告警
annotations:
summary: "{{$labels.instance}} 流入磁盘IO使用率过高,请尽快处理!"
description: "{{$labels.instance}} 流入磁盘IO大于90%,当前使用率{{ $value }}%."
- alert: 网络流入
expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance,job)) / 100) > 102400
for: 5m
labels:
severity: 严重告警
annotations:
summary: "{{$labels.instance}} 流入网络带宽过高,请尽快处理!"
description: "{{$labels.instance}} 流入网络带宽持续5分钟高于100M. RX带宽使用量{{$value}}."
- alert: 网络流出
expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance,job)) / 100) > 102400
for: 5m
labels:
severity: 严重告警
annotations:
summary: "{{$labels.instance}} 流出网络带宽过高,请尽快处理!"
description: "{{$labels.instance}} 流出网络带宽持续5分钟高于100M. RX带宽使用量{$value}}."
- alert: TCP连接数
expr: node_netstat_Tcp_CurrEstab > 10000
for: 2m
labels:
severity: 严重告警
annotations:
summary: " TCP_ESTABLISHED过高!"
description: "{{$labels.instance}} TCP_ESTABLISHED大于100%,当前使用率{{ $value }}%."
- alert: 磁盘容量
expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 90
for: 1m
labels:
severity: 严重告警
annotations:
summary: "{{$labels.mountpoint}} 磁盘分区使用率过高,请尽快处理!"
description: "{{$labels.instance}} 磁盘分区使用大于90%,当前使用率{{ $value }}%."修改配置文件
vim /usr/local/prometheus/prometheus/prometheus.ymlglobal:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- localhost:9093 # alertmanager地址,先写上
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "rules/*.yml" # 告警规则
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"] # 监控本主机
- job_name: 'alertmanager'
scrape_interval: 10s
static_configs:
- targets: ['localhost:9093'] # 监控alertmanager 主机
- job_name: 'node-exporter'
scrape_interval: 10s
static_configs:
- targets: ['localhost:9100'] # 监控节点,节点安装node_exporter
labels:
instance: Prometheus服务器验证数据
重启prometheus
systemctl restart prometheus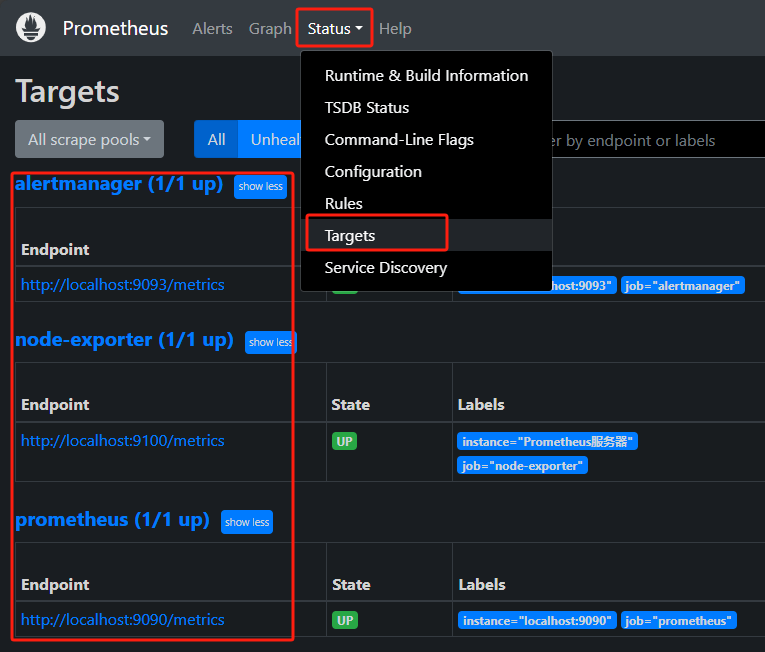
grafana集成prometheus
浏览器添加数据源

添加Prometheus地址,我这里是同一台安装,使用localhost
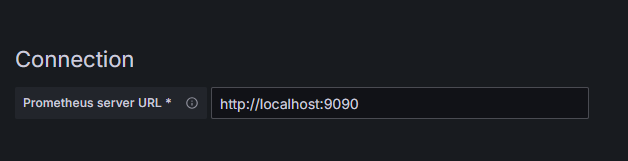
最后保存即可,不需要其他配置。
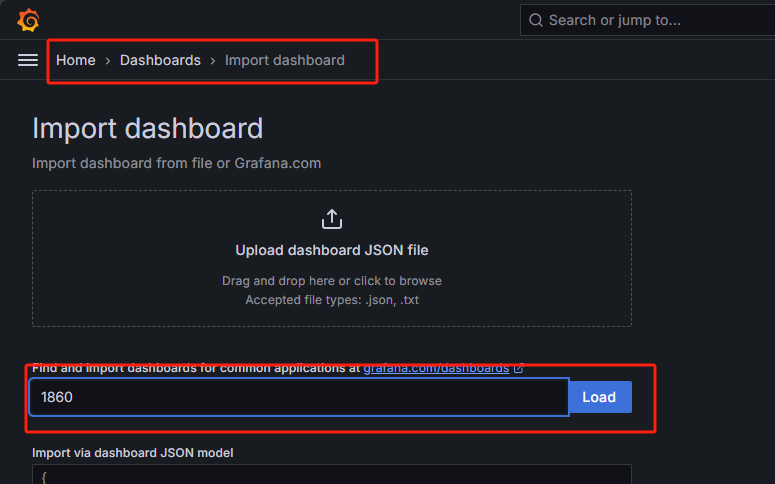
添加dashboard
这里使用1860id,节点监控仪表盘,更多仪表盘访问官方获取:Dashboards | Grafana Labs